Legal research increasingly turns to systematic analyses of large amounts of legal text. Current research programs such as Big Data Legal Scholarship, Evidence-Based Jurisprudence, Law & Corpus Linguistics, Computer-Assisted Legal Linguistics, and Law as Data all rely (one way or another) on digitizing or collecting, collectively analysing and quantifying features of text corpora from various genres. First and foremost among these genres are court decisions, due to both their normative force (either stare decisis, or de facto) and their easy and legally unconstrained useability: Court decisions are in the public domain pretty much everywhere (in Germany, Sec. 5 of the Copyright Act says so) and courts are obliged to publish their decisions in the public interest (in Germany, at least four. federal. supreme. courts. said so). So we need not worry that intellectual property may produce yet another availability gap like in digital humanities research, do we?
Should We Worry about Availability of Court Decisions?
Yes, we should. In most countries, major corpora of court decisions are published exclusively by commercial database providers on a subscription fee basis. In the US, PACER is infamous, but Germany’s primary legal databases (juris and Beck Online) are no different. In terms of the taxonomy of economic goods, court decisions are rarely „published“ in the sense of becoming public goods, but at best put into databases on an excludable basis as so-called club goods. (Some even remain private goods to the extent that they are never released at all, see 2. below.) Such restrictions in database access certainly constitute an intellectual property hurdle even for research on public domain texts. To acknowledge this hurdle and clarify the public goods issue at stake, we probably shouldn’t even speak of court decisions being „published“ so long as they will not be accessible to anyone without deliberate exclusions such as access fees.
Even assuming away such exclusions, however, any research on digitally available court decisions (including qualitative or doctrinal research) faces another availability challenge: Courts‘ reluctance to digitize. This has been documented by various studies in the US, including recent attempts to „Map the Iceberg“ in research on district courts, to tackle the „Problem of Data Bias“ in appellate court opinions, and to „Rebuild the Federal Circuit Courts“. Time and again, such studies find that courts do not release a sufficiently high percentage (or even representative samples) of their opinions to warrant generalizable claims from analyses of the public record. The only defense for still relying on the available corpus seems to be one articulated by the late father of Empirical Legal Studies Ted Eisenberg, along with Sheri Lynn Johnson, namely that published court decisions
“are representative – indeed, for most scholars they are the full population – of the cases shaping perceptions of the legal system. Published opinions are all most of us ever work from.”
This may have been a clever (albeit dangerous) defense back in 1991, but judging by the current potentials of digitalization it seems anachronistic, even downright circular: „We are justified to care about none but published court decisions, because those are the court decisions we have only ever cared about.“ Such an approach leaves a critical question unanswered, indeed unasked: What is the percentage of unavailable court opinions – i.e., the „blind spot“ – of a given jurisdiction of interest? In case law systems like the US, studies such as the ones mentioned earlier helped quantify this blind spot. For Germany, as a major statutory law system, I have recently conducted a similar study – indeed, to my knowledge the first longitudinal survey in any statutory jurisdiction. (I welcome pointers to earlier studies that I may have overlooked.)
Coverage Ratios and Blind Spots
I collected previously reported statistics, as well as additional newer data, into a hopefully comprehensive dataset, which enabled me to diachronically map the coverage ratio (Publikationsdichte) of German court decisions on private law issues. This coverage ratio denotes, for a given year, the number of court decisions that were accessible in a leading database (thus becoming at least club goods), divided by the number of court decisions rendered (in the same bin) according to official statistics. This percentage is the inverse of what I call the „blind spot“ of German legal research, and I elicited it over a period of almost fifty years since when the first digital transistor was invented in 1971.
My findings were published in the leading German law journal Juristenzeitung in 2021, and the following graph of the annual coverage ratio of German private law court decisions (across all tiers) summarises my main finding:
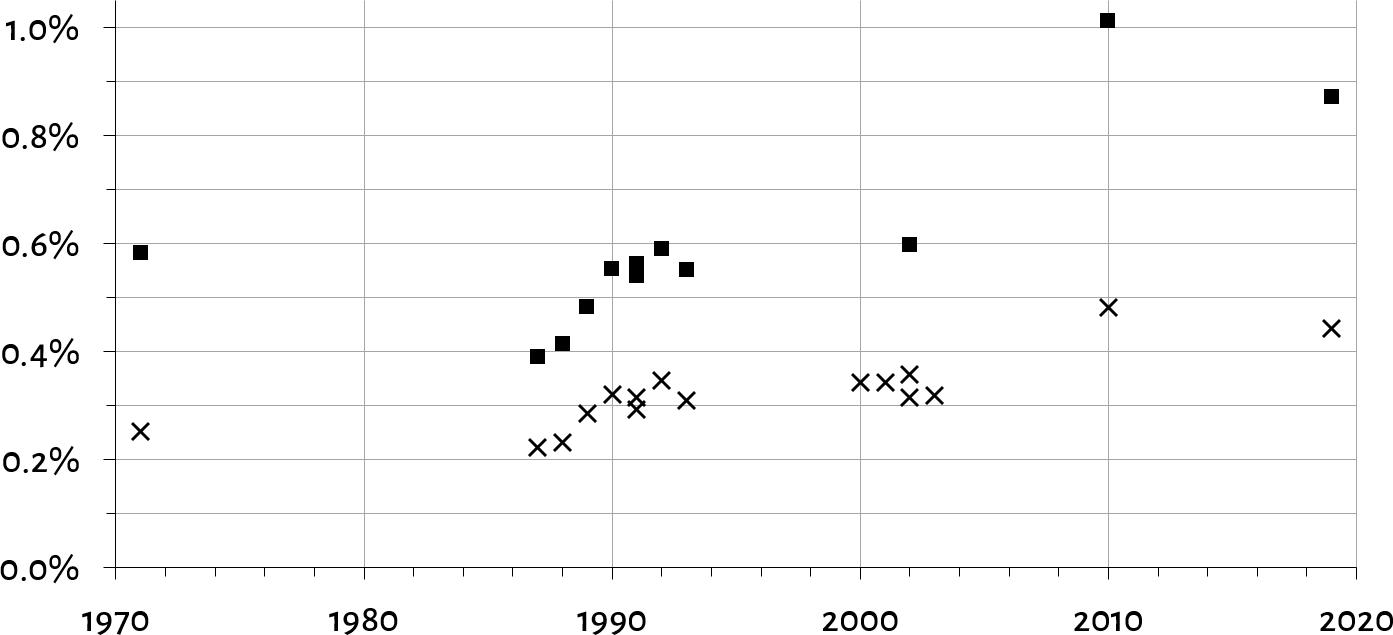
The square and cross symbols represent different ways of computing the coverage ratio metric (explained in the paper), based on data reported in four different studies since 1971, as well as my own data elicitation. They exhibit some fluctuation, but where studies‘ time-frames overlap so that multiple values were reported (in 1991 and 2002), I observe a high degree of reliability which should strengthen our confidence in the methodology.
The important thing to take away from the graph is that, no matter which study, no matter which year, no matter which metric: Never was the rate of available court decisions considerably higher than 1 percent. This means that in the same period where digital data storage density increased by over 33 million percent – from 199 Bytes/cm² in 1971 (8-inch floppy disk with 80 kB) to 666,370,683,501 Bytes/cm² in 2019 (0.5-inch microSDX card with 1 TB) –, the coverage ratio of judicial text data went, at best, from around 0.6 to 0.9 percent, indicating almost no relative progress throughout the entire history of digital technology development.
A few qualifiers on methodology: The coverage ratio obviously varies across court tiers, with higher coverage ratios in higher tiers of the judiciary, but (a) no court tier seems to approach 100 % coverage, with even a German supreme court reported to omit some eight percent of its decisions from the public record, and (b) removing data on higher tiers as unrepresentative for the judiciary would only lower the numbers reported earlier, painting an even bleaker picture of judicial transparency; the figures reported earlier should thus be read as charitable estimates. The coverage ratio also varies (slightly) across different databases, but the analyses rely on Germany’s oldest, most established and most authoritative database (owing to the German state establishing it, and still maintaining a 49.9 % financial interest), with other contenders entering the business much later than 1971. Also, the general trend seems to be so robust that even including additional subject matters (beyond private law adjudication) would, in all likelihood, yield substantively similar results. (I do hope for such replications to come forth.)
Mapping the Missing 99 Percent
Given these analyses, we can conversely map the blind spot of digital legal studies as comprising at least 99 % of all court decisions throughout the last half-century. I illustrated this in the second graph from my paper, the coverage ratio of court decisions in 1971 and 2019, displayed as a share of graph canvas area:

The white squares in the bottom left represent the share of court decisions that privileged users with database subscription can access (not download in bulk) while the grey area represents the share of court decisions that even money can’t buy. This illustration should teach us more than a modicum of modesty for our claims about „the legal system“ and the knowledge that digital (actually, any) legal research may afford us.
Some say that only five percent of the world’s oceans have been explored: If that is true, then our judicial precedents are an uncharted deep sea prior to the advent of submarines.
This post summarizes parts of my presentation „The Missing 99 Percent“ at the International Language and Law Association (ILLA)’s most recent Focus Conference „The Digitalisation of Legal Discourse“ at the University of Bergamo on 16 December 2021.
EDIT: Shortly before my talk, on 24 November 2021, the newly elected German government announced its policies on digitalisation, including a commitment that „anonymized court decisions should, as a matter of principle, be available in a public and machine-readable database“ (p. 106, lines 3570-3572 of the government’s Coalition Treaty). I have yet to meet an expert who expects this to actually happen on a large scale.


 Distributed under the Creative Commons License CC BY 4.0
Distributed under the Creative Commons License CC BY 4.0