Wenn wir von einer künstlichen Intelligenz (KI) wissen möchten, welches Tier ein Bild zeigt, muss sie zuvor auf Millionen Tierbildern trainiert worden sein. Wenn wir mit einer KI diskutieren möchten, benötigt die KI noch viel mehr Trainingsdaten. IBM’s Project Debater beispielsweise wurde auf 400 Millionen Zeitungsartikeln trainiert. ChatGPT, der Texte übersetzen, zusammenfassen und erzeugen kann (und bei der Erstellung dieses Beitrags mitgeholfen hat), wurde auf mehreren Terabyte Text aus unterschiedlichsten Quellen (Common Crawl, Wikipedia, …) trainiert. Aber was ist, wenn wir von einer KI wissen möchten, ob jemand eine Straftat begangen hat oder ob eine bestimmte Vertragsklausel rechtmäßig ist? In diesem Fall benötigt die KI zusätzlich juristische Daten in wohl mindestens der gleichen Größenordnung. Juristische Daten sind sämtliche juristische Literatur, Gesetzestexte und Materialien aus deren Entstehung, Verträge, Grundbücher, Urkunden, Schriftsätze, Gerichtsentscheidungen und so weiter. Um eine Vielzahl von juristischen Fragestellungen beantworten zu können, müssen die Trainingsdaten die Vielzahl und Vielfalt auch abbilden. Das heißt, es reicht nicht nur, dass jede mögliche juristische Fragestellung einmal in den Trainingsdaten auftaucht, vielmehr müssen für den maschinellen Lernprozess viele möglichst gleichgelagerte Fälle zu den jeweiligen Fragestellungen vorliegen. Bereits zur Klassifikation von Bildern unterscheidet beispielsweise der ImageNet Bilddatensatz mehr als 80.000 Klassen und zu jeder Klasse sind im Schnitt 1.000 Bilder vorhanden. Das lässt nur erahnen wie gigantisch groß ein Trainingsdatensatz für Legal Tech-Anwendungen sein müsste. Deshalb ist es wenig überraschend, dass bisherige Predictive Justice-Ansätze, die nur auf wenigen Hundert bis mehreren Tausend Entscheidungen trainiert wurden, nicht dazu genutzt werden können, beliebige Entscheidungen vorherzusagen.
Doch viele Daten allein reichen noch nicht. Die Daten müssen auch eine gewisse Qualität aufweisen, um zum Training genutzt werden zu können – insbesondere müssen sie maschinenlesbar sein. Während jedem klar ist, dass ein paar ausgeschnittene Zeitungsartikel oder unscharfe Katzenbilder aus dem letzten Urlaub nicht zum Training einer KI genügen, sollte ebenso klar sein, dass handgeschwärzte Gerichtsentscheidungen im PDF-Format genauso untauglich sind. Doch nicht nur ist das PDF-Format untauglich, es genügt auch rechtlichen Anforderungen nicht. Gerichtsentscheidungen sind zu veröffentlichen, da die Rechtsprechung für sie aus dem Demokratie- und Rechtsstaatsprinzip, sowie dem Justizgewährungsanspruch, eine Veröffentlichungspflicht ableitet. Neben anderen Voraussetzungen folgt aus dieser Pflicht, dass für die Bereitstellung von Gerichtsentscheidungen durch öffentliche Stellen das Datennutzungsgesetz (DNG) anwendbar ist.1 Das DNG soll gerade die Verwendung und Weiterverwendung offener Daten, sowie Innovationen fördern. Diese frei verfügbaren Daten müssen mitsamt Metadaten in einem maschinenlesbaren Format bereitgestellt werden. Es stellt sich die Frage, wie dem „Ob“ und „Wie“ der Veröffentlichung auf den öffentlich zugänglichen Rechtsprechungsportalen von den Ländern und dem Bund nachgekommen wird. Die nachfolgende Darstellung basiert auf einer eigenen Untersuchung,2 der zugrunde liegende Datensatz ist frei zugänglich.
1. Wie viel wurde veröffentlicht?
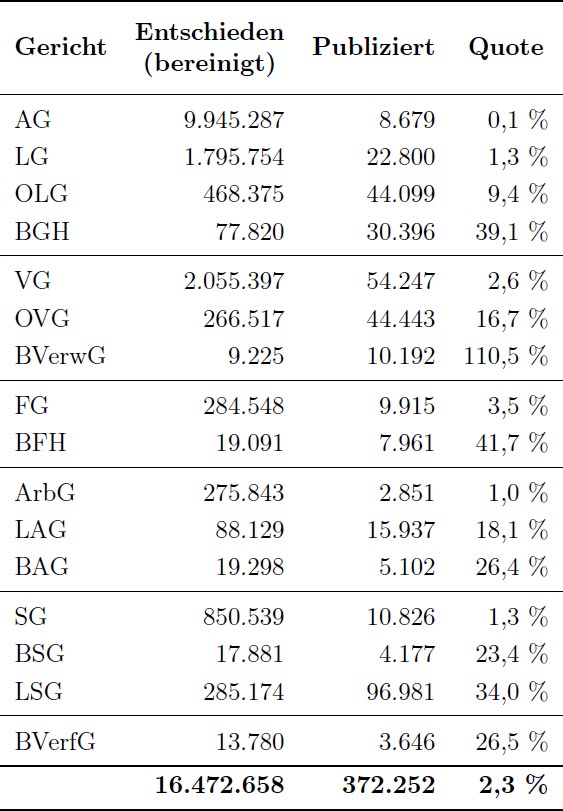
Um dieser Frage nachzugehen, wurden insgesamt 31 offizielle Portale des Bundes und der Länder zur Bereitstellung von Rechtsprechung berücksichtigt. Mittels Web Scraping wurden die auf den Portalen vorhandenen Informationen zu den Veröffentlichungen extrahiert. Dieser Vorgang war sehr aufwendig, da sich die Portale technisch teilweise sehr deutlich unterschieden. Von 2011 bis 2020 wurden in den Internetportalen von Bund und Ländern rund 372.000 Entscheidungen veröffentlicht (siehe nachstehende Tabelle). Diese Zahl wirkt niedrig angesichts der eingangs erwähnten notwendigen Größe eines Trainingsdatensatzes für Legal Tech-Anwendungen, die zur Lösung einer Vielzahl von rechtlichen Fragestellungen dienen sollen. Allerdings muss die Zahl der Veröffentlichungen vor dem Hintergrund betrachtet werden, wie viele Entscheidungen überhaupt ergangen sind und wie viele davon hätten veröffentlicht werden müssen.
2. Wie viel hätte veröffentlicht werden müssen?
Um das ungenutzte Potential der Veröffentlichungen aufzudecken, wurden die amtlichen Entscheidungsstatistiken herangezogen. In den Statistiken sind die Erledigungen der Gerichte erfasst, woraus sich ableiten lässt wie viele Gerichtsentscheidungen angefallen sind. Dabei dürfen natürlich nur solche Erledigungen berücksichtigt werden, die überhaupt erst zu einer begründeten Entscheidungen führen können. Um die übrigen Erledigungen, wie z.B. Klagerücknahmen oder Vergleiche, wurde die Entscheidungssumme bereinigt. Aus der bereinigten Entscheidungssumme ergibt sich Folgendes.
Im Zeitraum von 2011 bis 2020 hätten Bund und Länder nahezu 16, 5 Millionen Entscheidungen veröffentlichen können – und aufgrund der Veröffentlichungspflicht auch müssen. Diese Zahl bewegt sich schon eher in der eingangs diskutierten Größenordnung und zeigt damit, dass die Möglichkeit maschinelle Lernverfahren für Legal Tech-Anwendungen einzusetzen, nicht bereits von vorne herein mangels vorhandener Daten zum Scheitern verurteilt ist.
3. Bei welchen Gerichten und Gerichtsbarkeiten besteht noch Veröffentlichungspotenzial?
Setzt man die tatsächliche Anzahl der veröffentlichten Entscheidungen zur Anzahl der zu veröffentlichenden Entscheidungen ins Verhältnis, so ergibt sich eine bereinigte Veröffentlichungsquote von 2,3 % (siehe Tabelle).
Bricht man die Quote auf die Gerichte herunter, so bilden die Amtsgerichte das Schlusslicht mit einer Veröffentlichungsquote von nur 0,1 %. Auf Bundesebene bewegt sich die Veröffentlichungsquote von einem Viertel (BVerfG, BSG, BAG) über 40 % (BGH, BFH) hin zu über 100% (BVerwG). Veröffentlichungsquoten von über 100 % ergaben sich dadurch, dass die Gerichte mehr Entscheidungen veröffentlichten, als nach der Bereinigung typischerweise hätten veröffentlicht werden sollen. Das lag beispielsweise am vermehrten Veröffentlichen von Entscheidungen zur Prozesskostenhilfe, die ansonsten überwiegend nicht veröffentlicht wurden.
Insgesamt lässt sich feststellen, dass sämtliche Gerichte, bis auf das BVerwG, noch Potential bei der Veröffentlichung haben. Die Nutzung dieses Potentials ist nicht nur aus rechtstaatlicher Sicht geboten, sondern auch für Legal Tech-Anwendungen unerlässlich. Insbesondere ist problematisch, dass die Erstinstanzen die niedrigsten Veröffentlichungsquoten haben, was zu einer Unterrepräsentation ihrer Entscheidungen unter allen veröffentlichten Entscheidungen führt. Gerade bei diesen Instanzen werden viele gleichartige Fälle entschieden, die für das maschinelle Lernen essentiell sind. Denn im Gegensatz zum Menschen kann die Maschine aktuell nicht aus wenigen Beispielen den Kern einer rechtlichen Fragestellung extrahieren und daraus ein Modell konstruieren. Während der Mensch überwiegend anhand bundesgerichtlich entschiedener Spezialfälle sein grundsätzlich durch das Gesetz konstruiertes Modell einer rechtlichen Fragestellung vertiefen kann, muss die Maschine erst ein Modell anhand einer Vielzahl von gleichgelagerten Standardfällen erlernen. Diese gleichgelagerten Fälle werden in der Regel nicht vor den Bundesgerichten, sondern von den Eingangsinstanzen entschieden. Aufgrund der Zulassungsvoraussetzung zu den Revisionsgerichten kann dort ein bestimmtes Rechtsproblem nur einmal grundsätzlicher Klärung zugeführt werden. Folglich würde ein Training alleine auf obergerichtlichen Entscheidungen nicht ausreichen.
4. Wie erfolgte die Bereitstellung?
Die Veröffentlichung der Gerichtsentscheidungen von Bund und Ländern erfolgte nicht etwa in einem gemeinsamen Portal oder zumindest 16 Länder- und einem Bundesportal, sondern in 31 offiziellen Portalen.
Einige Bundesländer stellten lobenswerterweise alle veröffentlichten Entscheidungen ihrer Gerichte über ein Landesportal zur Verfügung. Jedoch wurden in manchen Bundesländern mehrere Portale oder gar Internetauftritte einzelner Gerichte zur Veröffentlichung eingesetzt. Außerdem tauchten manche Entscheidungen in mehreren Portalen auf.
Technisch zeichnete sich folgendes Bild. Nur 2 der 31 Portale stellten ihre Entscheidungen maschinenlesbar inklusive maschinenlesbarer Metadaten bereit. Der Rest stellte lediglich PDFs oder HTML bereit. Kein einziges Portal verfügte über eine Programmierschnittstelle (API) oder erlaubte Massendownloads. Möchte man maschinelle Lernverfahren auf Millionen von Entscheidungen trainieren, ist die aktuelle Art der Bereitstellung unzureichend. Erstens ist es viel zu aufwendig die Entscheidungen mittels Web Scraping zu extrahieren. Zweitens müssen Entscheidungen die in HTML oder als PDF vorliegen erst aufbereitet werden, um zum Training verwendet werden zu können. Maschinenlesbare Formate, wie XML, können hier Abhilfe schaffen, da sie ein leichtes Identifizieren und Extrahieren der Informationen aus der Entscheidung ermöglichen. Außerdem würde eine API oder zumindest ein Massendownload den Zugriff auf die Entscheidungen erheblich erleichtern, ebenso wie die Bündelung der Entscheidungen auf einem Portal.
5. Fazit
Die Veröffentlichungsquoten sind nicht erst von 2011 bis 2020 so niedrig, sondern seit Jahrzehnten. Dass der technische Fortschritt daran nichts geändert hat, ist verwunderlich. Es reicht nicht, die Quote in Zukunft zu steigern, vielmehr muss auch die Quote der Vergangenheit gesteigert werden, um die Altbestände dem Training von Legal Tech-Anwendungen zugänglich zu machen. Die Altbestände sind wichtig, weil zurückliegende Entscheidungen vielfach das Fundament der heutigen Rechtslage bilden.
Wir überlassen das Schlusswort zu dem Thema ChatGPT, um nochmal zu unterstreichen wie wichtig ein spezifisches Training ist: „Wenn Gerichtsentscheidungen so selten veröffentlicht werden wie ein neues Album von Daft Punk, dann wird Legal Tech wohl weiterhin in den 90ern hängenbleiben.“


 Distributed under the Creative Commons License CC BY 4.0
Distributed under the Creative Commons License CC BY 4.0