
Abb. 1: Die Gliederungsstruktur des BGB als kreisrunde Baumstruktur (Dendrogramm) mit gebogenen Kanten. DOI: 10.5281/zenodo.5468668
Juristische Netzwerkforschung in Deutschland
Die empirische Erforschung von juristischen Netzwerken hat in den letzten Jahren in Deutschland viel Aufwind erhalten, nicht zuletzt durch die Grundlagenarbeiten von Corinna Coupette und Kolleg:innen zu juristischen Netzwerken in Gesetzen, Verordnungen und Gerichtsentscheidungen (Coupette 2019; Coupette/Fleckner 2019; Katz et al. 2020; Coupette et al. 2021). Andere Autor:innen haben sich in jüngerer Zeit ebenfalls mit der statistischen Analyse von Netzwerken in BVerfG-Entscheidungen (Ighreiz et al. 2021) und in Bundesgesetzen (Gumpp/Schneider 2021) auseinandergesetzt.
Was ist Netzwerkforschung? Bei der Erforschung von Netzwerken geht es im Kern um die Analyse von Relationen zwischen Objekten. Was eine Relation („Edge“ oder „Kante“) und was ein Objekt („Node“ oder „Knoten“) ist, ist nicht definiert, sondern der Fantasie der Forscher:innen überlassen — eine große Freiheit und Bürde zugleich. Die Wirklichkeit („Netzwerk“) wird hierbei auf eine abstrakte mathematische Struktur („Graph“) reduziert. Objekte können beispielsweise juristische Aufsätze, Urteile, die Richter:innen selbst oder ganze Institutionen wie Gerichte sein. Relationen könnten Zitate, Aktenzeichen, Verwandschaftsgrade oder den Instanzenzug darstellen. Als Einführung in die juristische Netzwerkforschung besonders zu empfehlen ist das open access verfügbare Buch „Juristische Netzwerkforschung – Modellierung, Quantifizierung und Visualisierung relationaler Daten im Recht“ (Coupette 2019).
In Abbildungen 1 und 2 ist jeweils die Gliederungsstruktur (oder schlichter: das Inhaltsverzeichnis) des BGB abgebildet. Jeder Knoten ist eine Gliederungseinheit (ohne Einzelnormen), Kanten verbinden eine Gliederungseinheit mit ihrer jeweils über- und untergeordneten Ebene und bilden damit eine hierarchische Darstellung der inneren Systematik des Gesetzes. Das Handbuch der Rechtsförmlichkeit beschreibt die Zielsetzung der Gesetzesstruktur wie folgt (HdR 2008: Rn. 377):
Übergeordnete Gliederungseinheiten führen den systematischen Aufbau des Gesetzes vor Augen. Eine übergeordnete Gliederungseinheit fasst mehrere Einzelvorschriften unter einer Zwischenüberschrift zusammen, die den Inhalt stichwortartig angibt. Zwischenüberschriften helfen, ein Gesetz gut zu strukturieren (Rn. 372 f.), dienen der Übersichtlichkeit und können für die Anwender eine Auslegungshilfe sein.
Eine Herausforderung, der sich der Forschungsbereich als Ganzes allerdings noch stellen muss, ist der Abbau der Einstiegshürden. Derzeit erfordert der Einstieg in die juristische Netzwerkforschung (insbesondere das fachkundige Verständnis der veröffentlichten Forschung) erhebliche Methodenkompetenz in den mathematischen Disziplinen Graphentheorie, Statistik und Linearer Algebra, sowie in mindestens einer Programmiersprache. Für Spitzenforschung sind diese Anforderungen selbstverständlich nicht verhandelbar. Die ersten Schritte auf dem Weg dahin und die Integration der Ergebnisse in die traditionelle dogmatische Forschung können allerdings noch nutzerfreundlicher gestaltet werden.
Neue Netzwerkdaten im Corpus des Deutschen Bundesrechts (C-DBR)
Um die Einstiegshürden für Interessierte zu senken und die juristische Netzwerkforschung auch für weitgehend traditionell arbeitende Jurist:innen zu öffnen, habe ich begonnen, vorberechnete juristische Netzwerkdaten für konkrete Anwendungsfälle bereitzustellen, zunächst für die Analyse der Gliederungsstrukturen deutscher Gesetze und Verordnungen auf Bundesebene. Die Erforschung der inneren Struktur deutscher Rechtsakte steht noch ganz am Anfang, denn „[o]bwohl die Gesetzesgliederung als wichtiges Gestaltungsmittel der Legistik angesehen wird, und dies schon in der historischen Entwicklung der Gesetzgebungslehre war, entzieht sie sich bislang jeder wissenschaftlichen Systematisierung“ (Hamann 2015: 382).
Der von mir herausgegebene Corpus des Deutschen Bundesrechts (C-DBR) enthält ab der Version 2021-07-30 maschinenlesbare Gliederungsstrukturen — im Grunde das Inhaltsverzeichnis — (fast) aller deutschen Gesetze und Verordnungen. Sie sind berechnet aus den XML-Daten, die auf www.gesetze-im-internet.de zur Verfügung gestellt werden.
Die Netzwerkdaten sind im weithin bekannten Format GraphML codiert, welches sowohl mit grafischen Programmen (dazu sogleich) als auch mit Programmiersprachen wie Python und R gut verarbeitet werden kann. Die kleinste Ebene der bereitgestellten Daten ist aktuell die unterste Gliederungsebene, in einem zukünftigen Update wird es eine zusätzliche Variante mit den Einzelnormen als unterster Ebene geben.
Was meine ich mit „fast alle“? Am Stichtag (16. September 2021) verfügbar waren 6.638 Rechtsakte, von denen aber nicht für alle Rechtsakte auch Normtext bereitgestellt wird (ca. 1.000 Rechtsakte sind nur mit Metadaten nachgewiesen) und nicht alle Rechtsakte mit der dargestellten Methodik erfasst werden konnten. 233 Rechtsakte (in der früheren Version 2021-07-30 nur 24 Rechtsakte) konnten aus noch unklaren Gründen nicht analysiert werden (z.B. Fehler im XML, Fehler in meinem Code, keine Abkürzung vorhanden). Von den analysierten 6.405 Rechtsakten enthalten nach meinen Berechnungen 1.337 Rechtsakte (1.339 Rechtsakte in Version 2021-07-30) auch tatsächlich eine Gliederungsstruktur. Technisch gesprochen liegt dabei ein Graph mit zwei oder mehr Knoten vor, von denen einer aber immer von mir eingefügt wurde, um den gesamten Rechtsakt zu repräsentieren und in hierarchischen Visualisierungen ein „Zentrum“ bereitzustellen.
Dieses Ergebnis erscheint plausibel, und die Größenordnung deckt sich weitestgehend mit Angaben in der Literatur. So berichtete Hamann im Jahr 2015, dass nur 1.221 der von ihm am 5. Januar 2015 abgerufenen 6.332 Rechtsakte (5.315 mit Normtext) eine übergeordnete Gliederungsstruktur enthielten (Hamann 2015: 382-383, 385).1 Der Unterschied in den Zahlen kann auf unterschiedlicher Methodik beruhen (die Analyse von Hamann basiert auf regular expressions, der Extraktion von Zeichenketten durch syntaktische Regeln) oder sich schlicht dadurch erklären, dass seit 2015 etwa 100 Rechtsakte mit Gliederungsstruktur hinzugekommen sind. Der Source Code für die Methodik mit regular expressions ist mit freundlicher Genehmigung von Hamann zusammen mit dem Source Code für diesen Beitrag veröffentlicht. Zukünftige Forschung wird sich daher den Unterschieden im Detail widmen können.
Nach dem vom BMJV herausgegebenen Handbuch der Rechtsförmlichkeit sind bei „Gesetzen mit weniger als 20 Paragraphen (…) in der Regel keine übergeordneten Gliederungseinheiten erforderlich“ (HdR 2008: Rn. 378). Das würde den vorläufigen Schluss zulassen, dass ca. 80% der konsolidierten Rechtsakte des deutschen Bundesrechts sehr kurz sind und in der Regel weniger als 20 Einzelnormen enthalten (aber nicht müssen).

Abb. 2: Die Gliederungsstruktur des BGB als kreisrunde Baumstruktur (Dendrogramm) mit geraden Kanten. DOI: 10.5281/zenodo.5468668
Einfache Netzwerkanalysen für Einsteiger
Die in der Netzwerkforschung übliche analytische Trias von Mikro-, Meso- und Makroebene wurde von Coupette et al. auf die Erforschung von Netzwerken in juristischen Dokumenten wie folgt übertragen (Coupette et al. 2021: 5; siehe auch schon Coupette 2019: 71-73):
[…] enabling us to describe the legal system and its evolution in its entirety (macro level), through selected sets of legal documents (meso level), or using individual documents and their substructures (micro level) […]
Bezogen auf dieses Datenmodell lassen sich mit den im C-DBR bereitgestellten Daten grundsätzlich alle Ebenen beleuchten. Für die Makro- und Meso-Ebene eignen sich vor allem statistische Verfahren, die Mikro-Ebene und (ggf. mit einigem Aufwand) die Meso-Ebene können grundsätzlich auch mit qualitativen Analysen behandelt werden.
Wofür können die Netzwerkdaten des C-DBR konkret verwendet werden? Natürlich für komplexe mathematische Modelle, aber auch ganz einfach — mit nutzerfreundlichen grafischen Programmen — visuell aufbereitet für die eigene qualitative juristische Forschung und Lehre.
Zunächst könnten Sie schlicht eine anschauliche Visualisierung für Studierende erstellen, beispielsweise wie in diesem Beitrag für das BGB geschehen. Vielleicht möchten Sie aber auch das BGB (oder einen anderen Rechtsakt) vertieft analysieren und könnten verschiedene Ebenen oder verschiedene Gruppen von Gliederungseinheiten mit unterschiedlichen Farben darstellen (Beispiel: Coupette 2019: 7). Möglich ist auch ein synchroner Strukturvergleich verschiedener Rechtsakte um deren unterschiedliche Komplexität darzustellen, wie ihn Coupette und Fleckner für das BörsG, WpHG und AktG vorgenommen haben (Coupette und Fleckner 2019: 73). In Zukunft können Sie auch diachrone Vergleiche (über Zeit) vornehmen, sofern für verschiedene Zeitpunkte entsprechende Netzwerkdaten im C-DBR verfügbar sind (schönes Beispiel in Coupette und Fleckner 2019: 69).
Wie funktioniert es? Sehr einfach ist zum Beispiel die Nutzung der intuitiv bedienbaren Software „Gephi“, die sich in den Sozialwissenschaften bei der Analyse von Netzwerken großer Beliebtheit erfreut. Gehen Sie für eine qualitative Netzwerkanalyse von Rechtsakten im Corpus des Deutschen Bundesrechts (C-DBR) wie folgt vor:
- Interessanten Rechtsakt bestimmen und Abkürzung notieren (z.B: „BGB“). Im C-DBR stelle ich ein Verzeichnis aller Rechtsakte (inkl. Langtitel, Abkürzung und ID) zur Verfügung. Das Verzeichnis ist besonders dann hilfreich, wenn die Abkürzung ungewöhnlich oder unbekannt ist. Vergleichen Sie im Zweifel auch die ID.
- Gephi installieren: https://gephi.org (für Windows, Mac und Linux)
- Die „Netzwerke“-Variante des C-DBR herunterladen: https://doi.org/10.5281/zenodo.3832111
- [Optional] Aus dem Ordner „Netzwerkdiagramme“ der „Netzwerke“-Variante des C-DBR das automatisiert berechnete Diagramm mit der passenden Abkürzung bzw. ID (Beispiel: BGB_BJNR001950896.pdf) suchen und einen ersten visuellen Eindruck erhalten.
- Aus dem Ordner „GraphML“ der „Netzwerke“-Variante des C-DBR sich die .graphml-Datei mit der passenden Abkürzung bzw. ID suchen (Beispiel: BGB_BJNR001950896.graphml)
- Die GraphML-Datei in Gephi importieren
- Netzwerk in Gephi visualisieren und ggf. abspeichern
Achtung: Die berechneten Strukturen wurden noch nicht umfassend auf ihre Richtigkeit geprüft und sind daher noch als experimentell (!) einzustufen. Soweit Sie aus den Daten Netzwerkdiagramme mit Gephi erstellen und bei einer qualitativen Überprüfung mit dem jeweiligen Inhaltsverzeichnis keine Fehler entdecken, spricht andererseits auch nichts dagegen diese für die eigene Forschung und Lehre zu verwenden.
Ideen zur Visualisierung
Neben klassischen Netzwerkvisualisierungen lassen sich hierarchische Netzwerkdaten (wie sie bei Gliederungsstrukturen vorkommen) auch auf andere Arten visualiseren. Für die Visualisierung von Netzwerken gibt es nicht den einen, „besten“ Diagramm-Typ, die Auswahl bestimmt sich immer nach der Forschungsfrage und dem Kommunikationsziel, denn alle Arten von Diagrammen haben Vor- und Nachteile, die sorgfältig gegeneinander abgewogen und mit dem Kommunikationsziel in Einklang gebracht werden müssen.
Eine Möglichkeit sind Baumstrukturen (Dendrogramme), beispielsweise als kreisrunde Baumstruktur (Abbildungen 1 und 2) oder als klassische Baumstruktur (Abbildung 3):
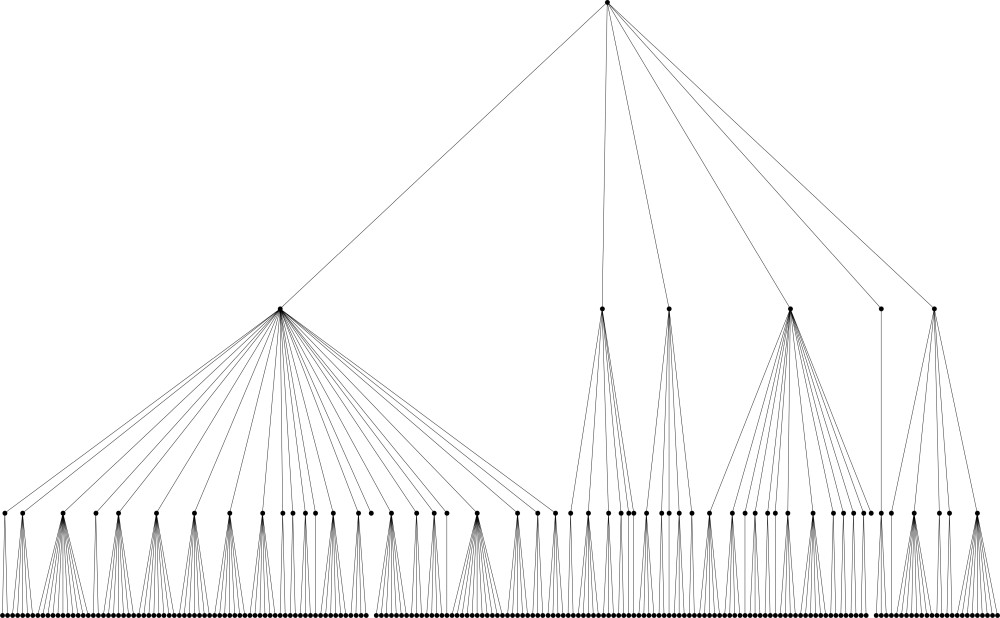
Abb. 3: Die Struktur des Börsengesetzes (mit Einzelnormen) vom 25. Juni 2017. Aus dem Online-Appendix zu Coupette und Fleckner 2019
An einer Visualisierung des BGB als klassische Baumstruktur (Coupette 2019: 7) erkennt man deutlich, wie die übliche Darstellungsform bei großen Gesetzen und wenig Platz in einem Buch (insbesondere bei Einbeziehung der Einzelnormebene) an ihre Grenzen stößt. Eine kreisrunde Baumstruktur ist besonders hilfreich, wenn die Knoten etikettiert werden sollen, weil dadurch mehr Platz für Text vorhanden ist (Abbildungen 1 und 2). Eine klassische Baumstruktur (Abbildung 3) bietet sich hingegen an wenn mehrere kleine bis mittelgroße Rechtsakte nebeneinander verglichen werden (Beispiel in Coupette und Fleckner 2019: 73).
Visualisierungen vom Typ „Circle Packing“ (Abbildung 4) und „Sunburst“ (Abbildung 5) können genauso bestechend und hilfreich sein. In den Abbildungen 4 und 5 ist ebenfalls die Gliederungsstruktur des BGB visualisiert. Das dunkelste Blau (Ebene 0) entspricht dem ganzen BGB, das nächste Blau (Ebene 1) den fünf Büchern, und so weiter, bis zur kleinsten Ebene (Ebene 6).
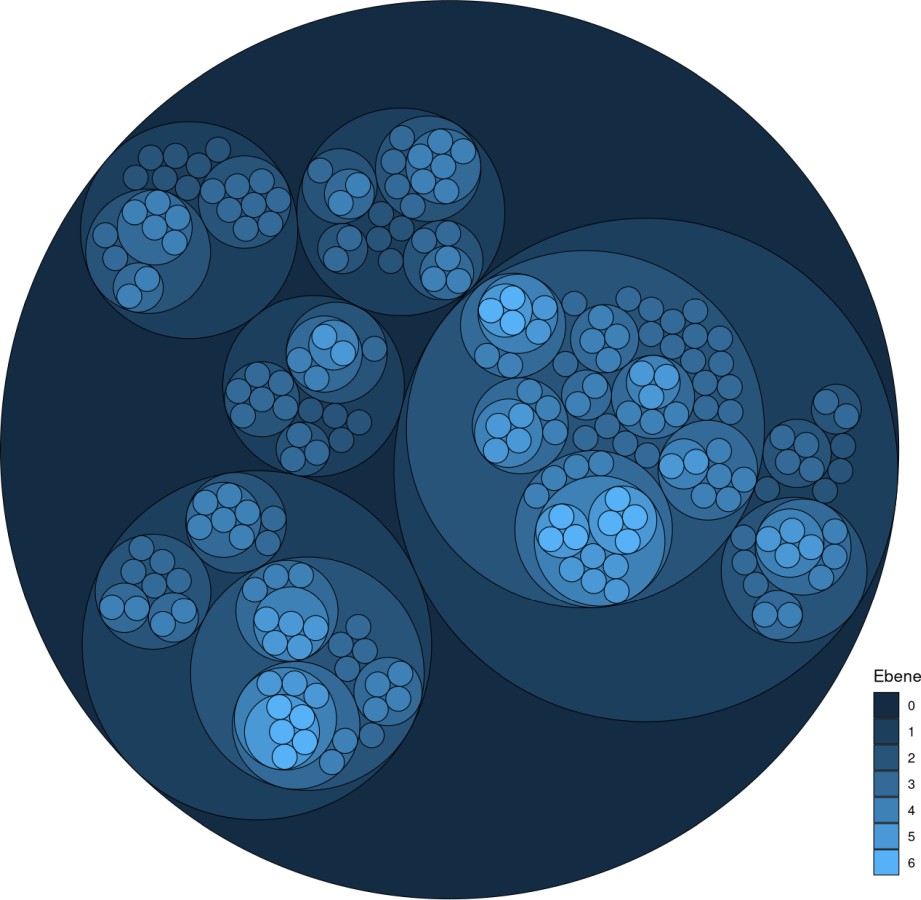
Abb. 4: Die Gliederungsstruktur des BGB als Circle Packing-Diagramm. DOI: 10.5281/zenodo.5468668
Circle Packing kann die relativen Verhältnisse zwischen Gliederungsgruppen gut darstellen. In Abbildung 4 ist zum Beispiel das relative Übergewicht des Schuldrechts an den Gliederungsebenen, gefolgt vom Familienrecht, besonders sichtbar.
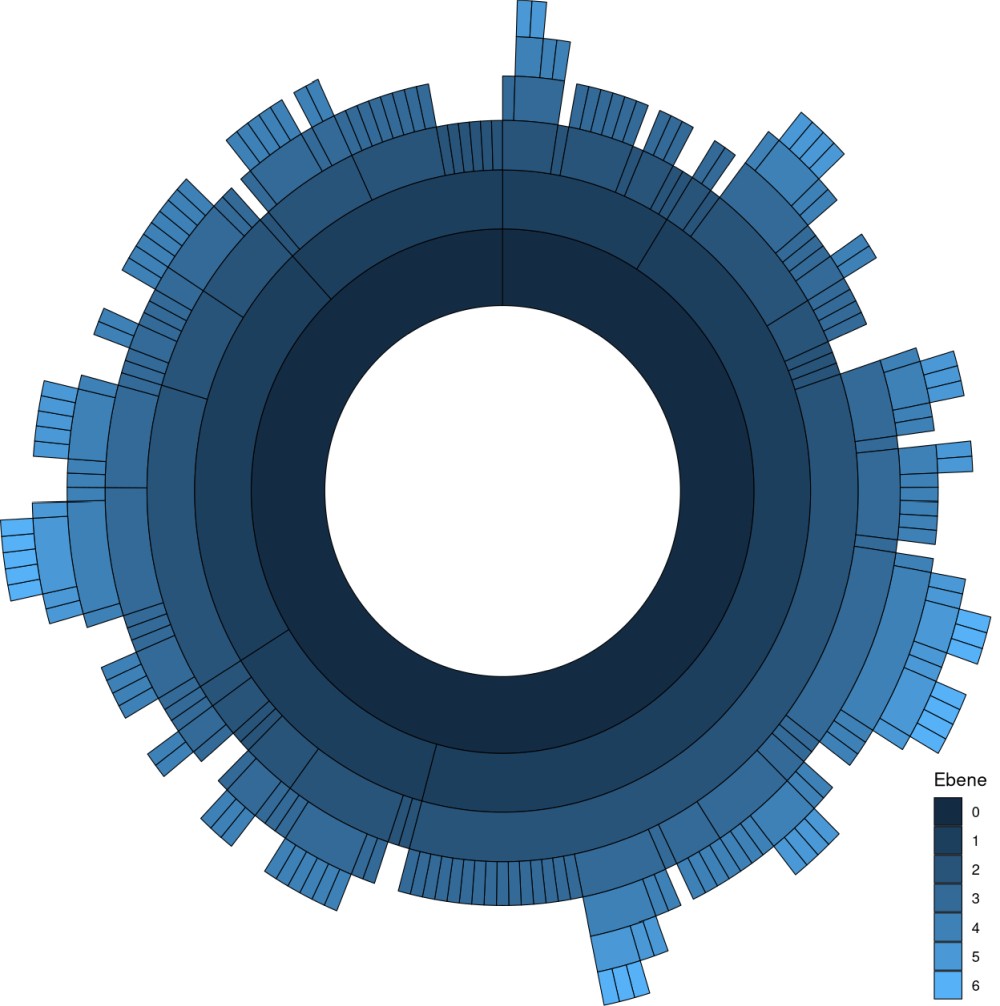
Abb. 5: Die Gliederungsstruktur des BGB als Sunburst-Diagramm. DOI: 10.5281/zenodo.5468668
Ein Sunburst-Diagramm (Abbildung 5) zeigt wiederum die einzelnen Ebenen besonders sauber und kann dadurch Tiefe am besten darstellen. Es ist auch platzsparender als eine klassische Baumstruktur. Selbstverständlich haben auch Circle Packing- und Sunburst-Diagramme Nachteile, beispielsweise die schwierige Etikettierung einzelner Teile (in diesem Fall werden interaktive Varianten empfohlen) und die radiale Darstellung, die das Ablesen einzelner Verhältnisse und Werte erschwert (Holtz 2021a, Holtz 2021b). In diesen Darstellungen verzichte ich daher auf eine Etikettierung und die Gewichtung einzelner Gliederungseinheiten (z.B. durch die Anzahl untergeordneter Einzelnormen).
Wichtiger Hinweis: In meinen Abbildungen (1, 2, 4 und 5) sind keine Einzelnormen (d.h. Paragraphen des BGB) mit einbezogen, entsprechende Visualisierungen könnten wiederum eine andere Interpretation nahelegen.
Methodik
Jede Gliederungsebene in der XML-Datei enthält einen XML-Tag namens „gliederungskennzahl“. Dessen Systematik ist weder vom Ministerium noch von der juris GmbH dokumentiert. Nach eingehender Analyse ist es sehr wahrscheinlich, dass diese Zahl in der Regel aus einer Aneinanderreihung von Tripeln besteht, die Auskunft über die Gliederungseinheit und ihrer übergeordneten Strukturen geben.
Die Tripel-Annahme scheint für die weit überwiegende Anzahl der Rechtsakte (inklusive dem BGB) korrekt zu sein, bei einigen wenigen Rechtsakten weicht die Gliederungsstruktur aber derart vom Normalfall ab, dass Hextupel und Tripel kombiniert werden.2 Das ist beispielsweise beim EGBGB so, in dem jeder Artikel als eine Gliederungsebene gilt. Dort werden die maximal möglichen 99 Gliederungsebenen der normalerweise genutzten Tripel durch die aktuell 253 Artikel des EGBGB überschritten und Hextupel kommen zum Einsatz. Rechtsakte mit Hextupeln sind derzeit noch nicht berücksichtigt, werden aber in Zukunft hoffentlich ebenfalls bereitgestellt werden.
Zum Verständnis: Tripel sind eine geordnete Auflistung von drei Elementen („Sequenz“), Hextupel eine Sequenz aus sechs Elementen. Die Reihenfolge der Elemente in einem Tripel oder Hextupel ist bedeutsam: (1, 2, 3) ist nicht dasselbe Tripel wie (2, 1, 3).
Jedes Zahlen-Tripel stellt eine Gliederungsebene dar und die ersten zwei Elemente des Tripels (ggf. mit vorangestellter Null falls kleiner 10) geben die Ordnungsziffer der Ebene an. Das dritte Element des Tripels ist in der Regel eine Null, kann aber erhöht sein, falls eine Ebene durch Buchstaben ausdifferenziert wurde.
Ein Beispiel aus dem Codebook: „010050030“, mit hervorgehobenen Tripeln: (0, 1, 0) (0, 5, 0) (0, 3, 0). Eine Länge von neun Elementen (d.h. drei Tripel) bedeutet, dass die Kennzahl der dritten Gliederungsebene zugeordnet ist. Hierarchisch steht sie unter der ersten Überschrift der 1. Ebene, der fünften Überschrift der 2. Ebene und stellt selber die dritte Überschrift der 3. Ebene dar.
Die Übersetzung der Gliederungsstruktur der Rechtsakte in eine Netzwerkstruktur baut ganz wesentlich auf dem XML-Tag „gliederungskennzahl“ auf und steht und fällt selbstverständlich mit der Qualität der bereitgestellten Strukturdaten und der Richtigkeit meiner eigenen Interpretation derselben. Die Netzwerkdaten sollten daher als experimentell eingestuft und vor der Weiternutzung immer auf ihre Richtigkeit überprüft werden (z.B. durch Abgleich der Visualisierung mit dem eigentlichen Inhaltsverzeichnis).
Die technische Umsetzung der Analyse beruht auf der statistischen Programmiersprache R (R Foundation for Statistical Computing 2021), und den packages igraph (Csárdi et al. 2020) und ggraph (Pedersen 2021).
Natürlich ließe sich die Gliederungsstruktur auch auf andere Arten rekonstruieren, beispielsweise durch die Analyse des Volltextes auf entsprechende Zeichenfolgen mittels regular expressions (REGEX), wie von Hamann vorgenommen. Ob eine alternative Vorgehensweise weniger fehleranfällig ist, ist derzeit wissenschaftlich noch nicht geklärt. Angesichts der von Hamann aufgezählten Widersprüche und Besonderheiten (Hamann 2015: 392-394) ist eine fehlerfreie REGEX-Analyse jedenfalls nicht trivial und bedarf intensiver Validierung.
Source Code und Feedback
Der vollständige Source Code für die Konstruktion des C-DBR und die Berechnung der Netzwerkstrukturen ist hier verfügbar: Source Code des C-DBR. Der Beitrag basiert auf Version 2021-09-16 des C-DBR.
Der vollständige Source Code für die von mir erstellten Visualisierungen in diesem Beitrag (inklusive hochauflösender Fassungen aller Diagramme für die freie Weiterverwendung) ist hier verfügbar: Source Code und Analyse-Ergebnisse dieses Beitrags. Der Beitrag basiert auf Version 1.0.0 des Source Codes und der Diagramme.
Wie bereits erwähnt sind die berechneten Strukturen noch nicht vollständig auf Richtigkeit geprüft. Über Hinweise auf Fehler und Verbesserungsvorschläge freue ich mich sehr, am besten im Issue Tracker des C-DBR auf GitHub oder per E-Mail (fobbe-data@posteo.de).
Der Autor bedankt sich ganz herzlich bei Dr. Corinna Coupette, Dr. Dr. Hanjo Hamann und Dr. Lucia Sommerer für viele hilfreiche und konstruktive Anmerkungen zu diesem Beitrag.

- Hamann nennt 5.315 untersuchte Rechtsakte, davon 4.094 ohne Gliederungsstruktur, macht 1.221 Rechtsakte mit Gliederungsstruktur (Hamann 2015: 385).
- Herzlichen Dank an Corinna Coupette für den Hinweis.

 Distributed under the Creative Commons License CC BY 4.0
Distributed under the Creative Commons License CC BY 4.0