Die Didaktik der Rechtswissenschaft ist ein stetig wachsendes Forschungsgebiet im Spannungsfeld von allmählicher wissenschaftlicher Durchdringung und teils hitziger Reformdiskussion. Dafür sind belastbare empirische Erkenntnisse besonders wichtig, um beurteilen zu können, welche didaktischen Innovationen hilfreich sind, wo Verbesserungspotentiale bestehen und wie die juristische Ausbildung wirklich „funktioniert“. Ein R|E Online-Symposium widmet sich diesen Fragen und lässt im Verlauf mehrerer Monate Wissenschaftler:innen aller Karrierestufen zu Wort kommen. (Red.)
Im Jurastudium eine gute Klausur zu schreiben, ist nicht einfach. Diese Klausur gut zu bewerten, ist genau so schwierig. Damit diese Bewertung gut ist, sollte sie so begründet sein, dass die Begründung für die Person, die die Klausur bearbeitet hat, nachvollziehbar und hilfreich ist. Idealerweise sollte die Bewertung auch noch objektiv, valide und reliabel sein. Diese drei Begriffe stellen die Hauptgütekriterien dar, nach denen man in der Psychometrie bewertet, ob ein Test verlässlich das testet, was er soll. Objektiv ist ein Test, wenn die Ergebnisse eines Tests unabhängig von der untersuchenden Person sind. Reliabel ist der Test, wenn der Messwert zuverlässig ist, valide ist der Test, wenn er das misst, was er zu messen beansprucht. Sind juristische Klausuren (zumindest in einem akzeptablen Maße) objektiv, reliabel und valide? Ich habe Grund zur Annahme, dass das nicht der Fall ist. In meinem Aufsatz „Jede Korrektur eine andere Note: Quantitative Untersuchung der Objektivität juristischer Klausurbewertungen“ in der ZDRW 1/2024 S. 59 ff. habe ich das erste dieser drei Kriterien untersucht. Im Ergebnis scheint die Bewertung von Anfängerklausuren wenig objektiv zu sein. Ohne Objektivität fallen auch die anderen beiden Hauptgütekriterien (Reliabilität und Validität) weg, da ein Test nicht das testen kann, was er beansprucht, wenn das Ergebnis nicht hinreichend von der Leistung abhängt. Hier ist in vielen Bereichen mehr Forschung nötig.
Design des Experimentes
Ich habe insgesamt 30 Personen angefragt, jeweils 10 Klausuren zu korrigieren. Alle wären qualifiziert gewesen, diese Klausur an der Uni auch tatsächlich zu korrigieren, was bedeutet, dass sie am Lehrstuhl arbeiten oder dies von den Noten könnten. Ich sehe eine gewisse Grundironie darin, die Auswahl der Korrektorinnen und Korrektoren mit dem Kriterium zu legitimieren, das das Ergebnis des Experiments zu delegitimieren scheint. Da die juristische Welt in Bezug auf fast alle Jobs, auch die akademische Welt, einen hohen Wert auf die Noten legt, muss hier eine gewisse kognitive Dissonanz aufrechterhalten werden. Diesen Personen habe ich 10 anonymisierte und getippte Klausurbearbeitungen, den Sachverhalt und die Lösungsskizze geschickt, mit der Bitte, mir die Noten zu übermitteln. Da ich keine Forschungsgelder zur Verfügung hatte, habe ich allen im Vorfeld die gleichen Informationen über das Experiment gegeben, woraufhin diese aus Interesse an dem Projekt ihre Arbeitszeit investiert haben. Von den 30 Personen haben 23 jeweils 10 Klausuren korrigiert und mir die Noten übermittelt, wodurch ich 230 Korrekturen über 15 Klausuren zum analysieren hatte. Die Klausuren waren in drei Gruppen von je 10 Klausuren aufgeteilt, also Klausuren 1-10, Klausuren 5-15, Klausuren 1-5 und 10-15. Gruppe 1 wurde 16 mal korrigiert, Gruppen 2 und 3 je 15 mal.
Die Analyse der Ergebnisse habe ich größtenteils mit Python Pandas durchgeführt, die Visualisierung mit seaborn. Der Code und die Daten sind hier zu finden.
Die Klausur, die ich genommen habe, ist eine zweistündige Anfängerklausur im Verwaltungsrecht, die während der Coronapandemie von Studierenden der LMU im Tutorium Verwaltungsrecht (Leitung Dr. Martin Heidebach, dem ich sehr herzlich für die Ermöglichung und die Unterstützung danke) am Computer und von zuhause als freiwillige Probeklausur geschrieben wurden.
Ergebnisse
Da es aus meiner Sicht noch keine vergleichbaren veröffentlichten Experimente gibt, wollte ich die Analyse nicht überfrachten, sondern die Aussage darauf reduzieren, dass Unterschiede existieren und ungefähr sagen können, wie groß diese Unterschiede sind. In dieser Hinsicht zeigen die Ergebnisse erhebliche Unterschiede auf.
Der durchschnittliche Unterschied zwischen der niedrigsten und höchsten Note, die zwischen den 16 oder 15 Korrekturen pro Klausur vergeben wurde, liegt bei 6,47. Wenn also die niedrigste Bewertung einer Klausur bei 4 Punkten lag, liegt die höchste Bewertung derselben Klausur im Durchschnitt bei 10,5.
Ich habe auch die Varianz und die Standardabweichung der Korrekturen berechnet. Hier wäre es für die juristische Welt gut, wenn sich die hohen Durchschnittswerte in der Abweichung dadurch erklären ließen, dass es zwar Ausreißer nach oben oder unten gibt, aber die meisten Ergebnisse sehr nah am Durchschnitt liegen. Leider ist das nicht so. Ich habe eine fiktive Klausur, die die Durchschnittswerte aller Ergebnisse annimmt (Bewertung von 6,83, Standardabweichung von 1,85), genommen. Wenn man eine solche Kurve standardisiert, kann man die Fläche unter der Kurve als Maß nehmen, wie häufig ein Vorkommnis in dem betrachteten Bereich liegt. Nach den hier gemessenen Ergebnissen liegen nur 42% der Ergebnisse innerhalb ± 1 Punkt vom Durchschnitt der Klausur. Als Beispiel: eine Klausur hat einen Durchschnitt von 6 Punkten; es ist zu erwarten, dass 58% aller gegebenen Noten außerhalb des 3-Punkte-Bereiches 5-7 Punkte liegen.
Für alles Weitere möchte ich Sie auf den Aufsatz verweisen, der diese Ergebnisse ausführlicher diskutiert.
Weitere Gedanken
Hier möchte ich noch einige andere Gedanken zu den Daten aufschreiben, die im Aufsatz keinen Platz gefunden haben. Man kann sich an den verschiedenen stochastischen Momenten orientieren, um noch weitere Aussagen zu treffen. Wenn man zum Beispiel das folgende Histogramm einer Gruppierung aller Ergebnisse betrachtet:
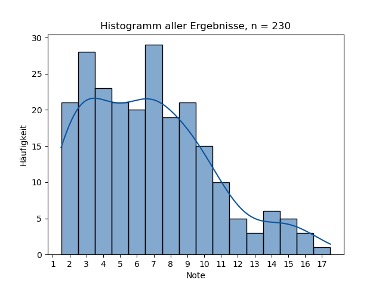
Sieht man schon, dass die juristische Notenskala schief verteilt (skewed) ist, in diesem Fall redet man von Rechtsschiefe. Das spricht dafür, dass die Notenskala nicht um die 9 Punkte herum verteil ist, was aus Innenperspektive für Juristinnen und Juristen offensichtlich ist. 9 Punkte sind schließlich eine exzellente Note und das begehrte „Vollbefriedigend“. Aus prüfungstechnischer Sicht fragt man sich aber, was eine Skala soll, die nicht genutzt wird. Zum einen gibt es Bereiche, die vollends überflüssig sind. Wieso gibt es 4 verschiedene Abstufungen des durchgefallenen Notenbereiches (Noten 0, 1, 2, 3)? Das an sich grenzt an Schikane und könnte problemlos durch eine einzige Kategorie ersetzt werden („nicht bestanden“). Am oberen Ende gibt es ebenso sinnlose Notenbereiche. „Sehr gut“, also 14-18 Punkte erreichen im Examen nur 0,2% der Absolventinnen und Absolventen. Einen Notenbereich von 38% der Skala für 0,2% der Personen zu reservieren, erscheint absurd. Selbst den Bereich des „Gut“, also ab 11,5 Punkten, erreichen nur 3,5% der Personen. Man könnte also den gesamten Bereich ab 11,5 Punkten, der unter 4% aller Kandidatinnen und Kandidaten umfasst, zu einer Note zusammenfassen, etwa „Herausragend“. Ein alternatives System wäre, die Noten nicht bekannt zu geben und die Prüfung mit „Wettbewerbscharakter“ (vgl. Art. 16 Abs. 1 S. 2 BayJAPO) dahingehend ernst zu nehmen, dass Klausuren zwar bewertet werden, aber nur das Perzentil im Verhältnis zum Jahrgang anstatt der Einzelnote genannt wird. Dies würde auch die mangelnde Vergleichbarkeit zwischen Jahrgängen beheben und wäre auch bei Probeklausuren gut umsetzbar. Mindestens könnte dies zur Note zusätzlich genannt werden. Eine Bewertung „7 Punkte, das ist besser als 64%“ ist mutmaßlich motivierender als bloß „7 Punkte“.
Es wäre theoretisch eine Skala ausreichend, die drei Bereiche umfasst: durchgefallen, bestanden, stark bestanden, mit Verteilungen von etwa 25%/60%/15%. Solange die juristische Welt ihr Notenfixierung beibehält, würde eine solche Skala mutmaßlich nicht angenommen werden.
In Hinblick auf die Varianz war meine Hoffnung, dass es Bereiche im unteren und im oberen Notenspektrum gibt, die „stabil“ sind, also geringere Varianz als mittlere Klausuren im Bereich 6-8 Punkten aufweisen. Das hat sich leider nicht bestätigt. Hierzu folgendes Diagramm:
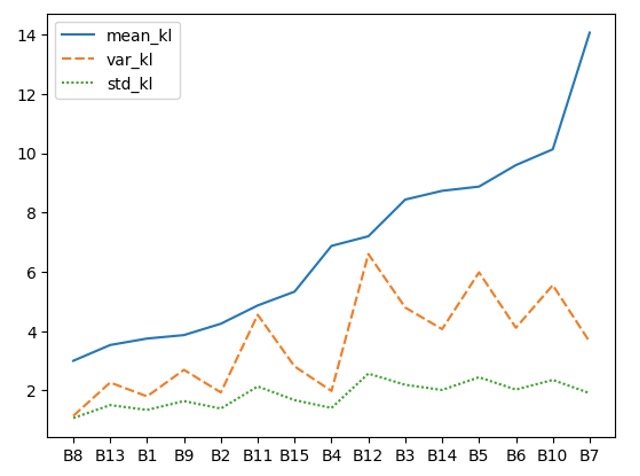
Auf der x-Achse sind die verschiedenen Bearbeitungen, sortiert nach ihrer durchschnittlichen Bewertung (blaue Linie, „mean_kl“) von niedrig zu hoch. Gleichzeitig sind die Varianz und die Standardabweichung als orangene gestrichelte und grüne gepunktete Linie zu sehen. Es scheint nach dieser Abbildung, dass die Varianz mit steigender Note tendenziell auch eher steigt. Dass die besten vier Klausuren eher stagnieren, statt einen Trend zu wachsender Varianz aufzuzeigen, kann genau so gut zufällig sein. Hier müssen mehr Klausuren analysiert werden, um belastbare Aussagen zum Verhältnis von Varianz und Qualität der Klausur zu treffen.
Weitere Forschung
Die Möglichkeiten und der Bedarf sind gleichermaßen groß. Ich fordere Sie gerne dazu auf, hier tätig zu werden. Mein Aufsatz war auf die Existenz von Unterschieden beschränkt. Die weitere Erforschung der Ursachen solcher Unterschiede ist klassische sozialwissenschaftliche Forschung. Faktoren wie Alter, Geschlecht, geographischer Standort, eigene Examensnoten, Beruf oder Stimmung der korrigierenden Person wären alle wert, untersucht zu werden. Auch Modalitäten der Korrektur, wie Tageszeit, Anzahl der Klausuren, Reihenfolge der Klausuren im Stapel, Qualität der unmittelbar vorhergehenden Klausur, Ankereffekte (Stichwort: verdeckte Zweitkorrektur) oder Vorgaben zur Korrektur können auch alle wertvolle Beiträge zu faireren Prüfungen liefern.
Das wichtigste ist, dass wir als Juristinnen und Juristen besser verstehen, wie sich unser jetziges Prüfungssystem und andere mögliche Prüfungssysteme empirisch verhalten, um gut informierte politische Entscheidungen darüber zu ermöglichen


 Distributed under the Creative Commons License CC BY 4.0
Distributed under the Creative Commons License CC BY 4.0